9. Airflow Deepdive 2
scheduler : 특정 DAG를 정해진 시간에 실행
task : 실행해야 할 코드
멱등성을 고려하도록 하는 job은 ETL에서 L의 역할에 좀더 가까움
ETL과 ELT의 차이
ETL : 하나의 데이터 파이프라인(하나의 DAG)
ELT
아키텍처에 가까운 용어
데이터를 소비하는 패턴. summary table을 만듦. 처리하는 데이터가 큼. ETL을 통해 적재된 데이터를 묶어 새로운 정보를 만들어내는 패러다임
여러 소스에서 데이터를 추출해 데이터 레이크를 형성(Load) 이후 Transform
일단 Load를 해두기 때문에 정형, 비정형 데이터 모두 보관을 할 수 있음
이후에 필요한 데이터만 뽑아서 사용할 수 있기 때문에 처리를 함에도 용이
클라우드 스토리지 시스템의 발달로 가능해진 아키텍처
summary table을 만드는 것과 비슷한 컨셉
CTAS시 SELECT문의 ORDER BY는 지켜지지 않음
ETL의 transform에 비식별화, 마스킹 처리 등도 포함됨
DAG에서 task를 어느 정도로 분리하는 것이 좋을까?
task를 많이 만들면 전체 DAG가 실행되는데에 오래 걸리고 스케줄러에 부하가 감
task를 너무 적게 만들면 모듈화가 안되고 실패시 재실행 시간이 오래 걸림
오래 걸리는 DAG여서 실패할 경우 재실행이 쉽게 다수의 task로 나누는 것이 좋음
MySQL 테이블 복사하기
프로덕션 데이터베이스(MySQL) → 데이터 웨어하우스(Redshift)
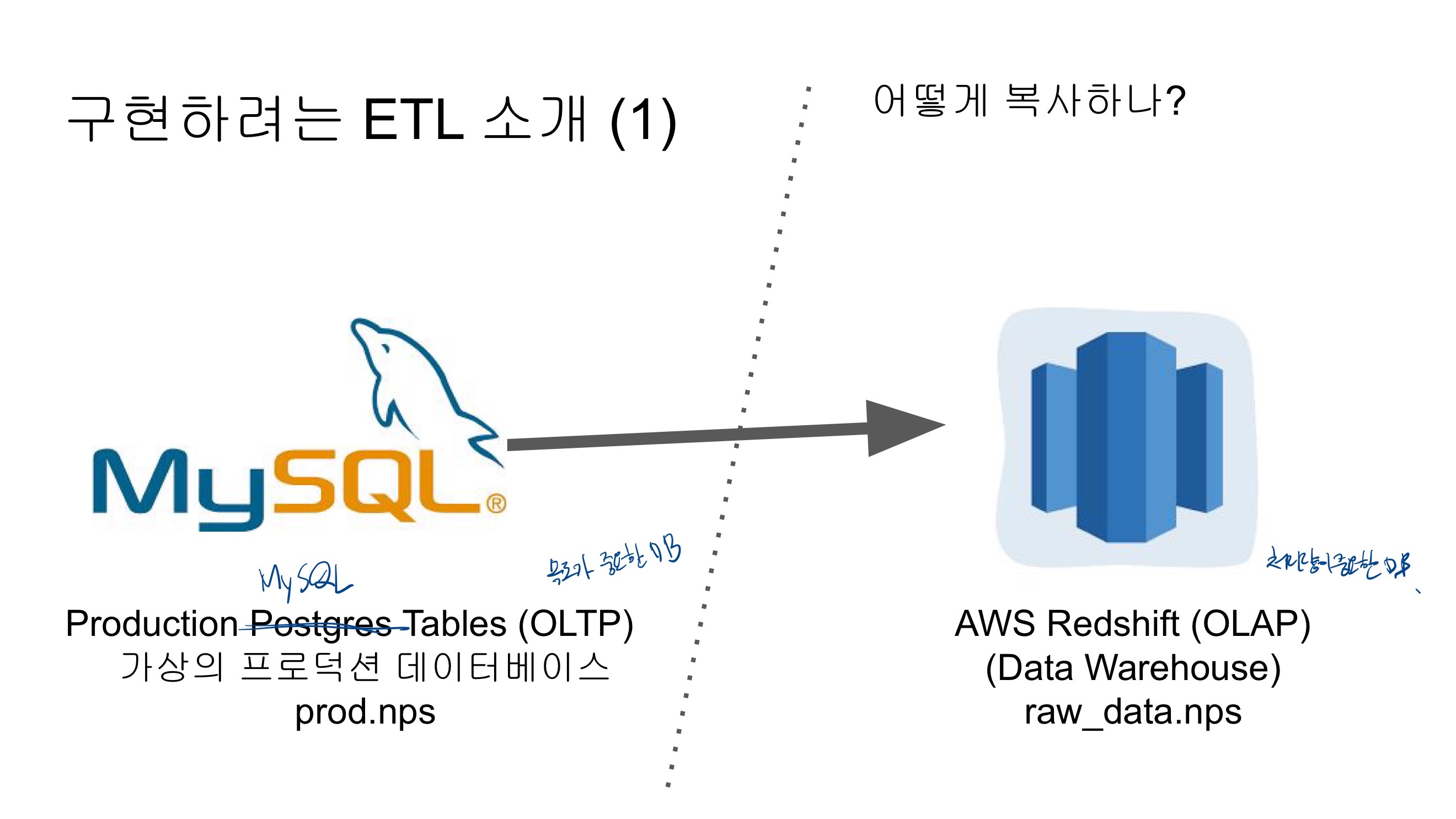
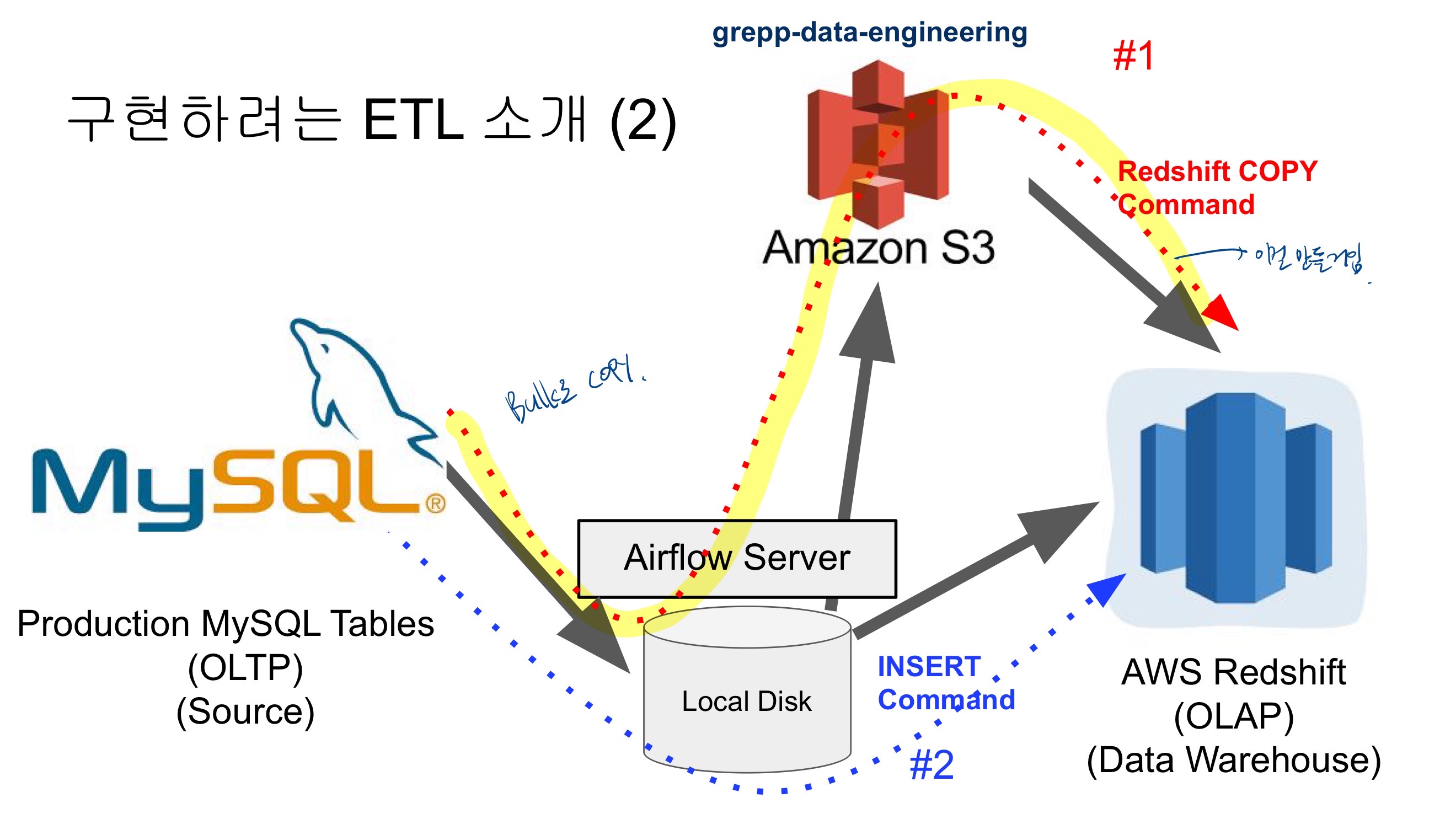
MySQL에 저장된 가상의 프로덕션 DB의 데이터를 Redshift로 적재하는 데이터 파이프라인을 구성
S3DeleteObjectOperator를 사용해서 주어진 버킷 키에 파일이 존재하면 삭제하도록 함
How to Make Your DAG Backfill ready
모든 DAG가 backfill을 필요로 하지는 않음 → full refresh를 한다면 backfill은 의미가 없음
여기서 backfill은 일별 혹은 시간별로 업데이트하는 경우를 의미함
→ 마지막 업데이트 시간 기준 backfill을 하는 경우라면 (DW 테이블에 기록된 시간 기준) 이런 경우에도 execution_date를 이용한 backfill은 필요하지 않음
데이터의 크기가 굉장히 커지면 backfill 기능을 구현해 두는 것이 필수
어떻게 backfill로 구현할 것인가?
→ 제일 중요한 것은 데이터 소스가 backfill 방식을 지원해야 함
→ execution_date를 사용해서 업데이트할 데이터 결정
→ catchup 필드를 True로 설정
→ start_date/end_date를 backfill하려는 날짜로 설정
→ 다음으로 중요한 것은 DAG 구현이 execution_date를 고려해야 하는 것이고 idempotent해야함
'Data Enginerring > 데이터 엔지니어링 스타터 키트' 카테고리의 다른 글
| 프로그래머스 데이터 엔지니어링 스터디 9기 수강 후기 (0) | 2022.09.21 |
|---|---|
| [5주차] Airflow 소개 (1) | 2022.09.20 |
| [4주차] ETL(Extract, Transform and Load)과 Airflow (0) | 2022.09.14 |
| [3주차] 데이터 엔지니어링을 위한 SQL (0) | 2022.09.12 |
| [2주차] Cloud & AWS 그리고 Redshift (0) | 2022.09.08 |