8. Airflow Deepdive
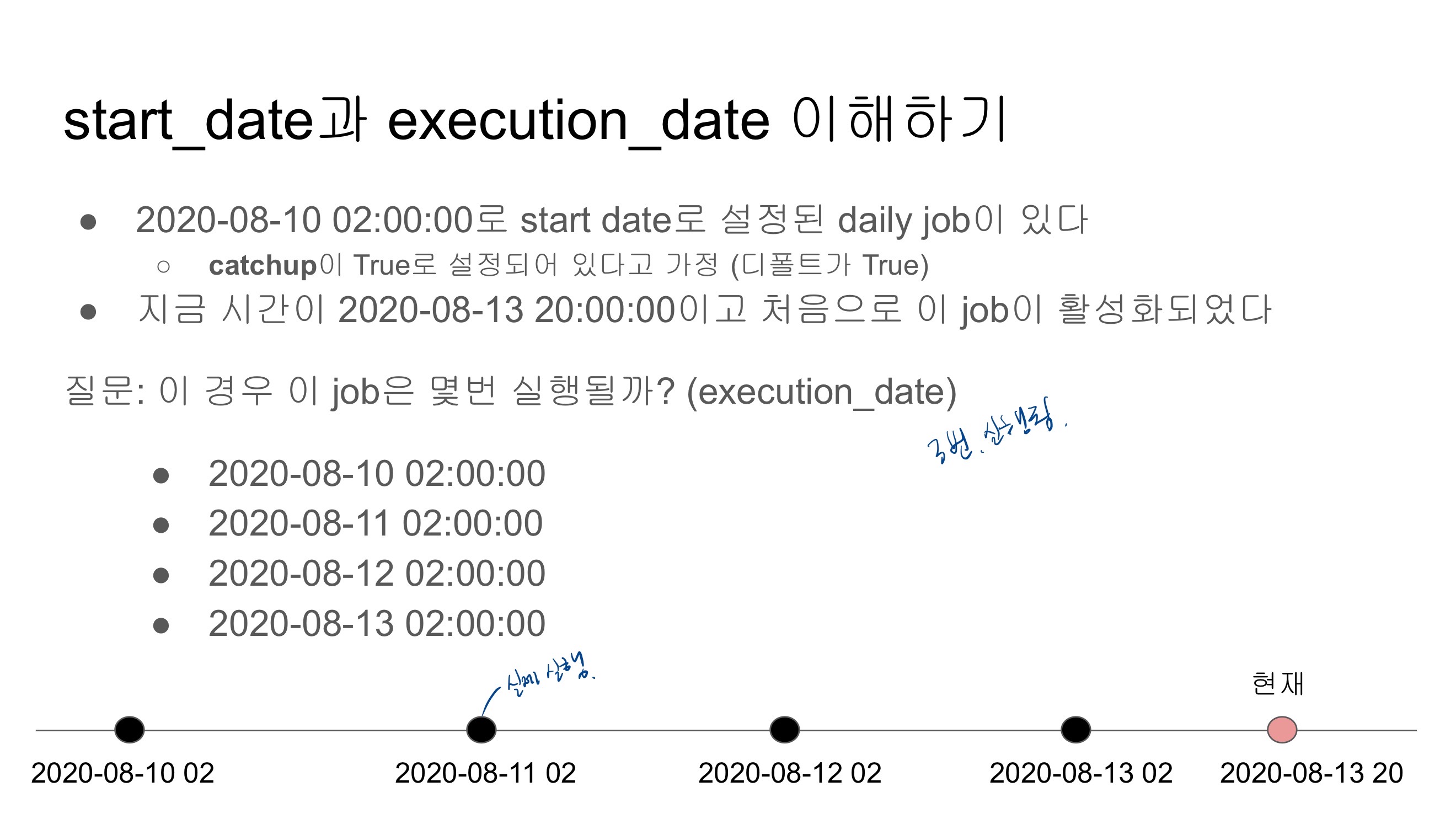
start_date
DAG의 처음 실행 시간이 아님
Incremental update를 구현한다고 가정했을 때 처음 읽어와야하는 데이터의 날짜 Airflow는 DAG를 Incremental update로 가정함
daily job이라면 start_date + 하루 가 실제 DAG의 첫 실행시간
hourly job이라면 start_date + 한시간 이 첫 실행시간
→ schedule interval로 결정
start_date + 실행주기가 처음 실행시간이 됨
execution_date
full refresh를 할 때는 중요하지 않음. incremental update를 할 때 중요
airflow가 제공해주는 시스템 변수로 읽어와야할 데이터의 날짜와 시간이 들어옴
한번 구현해서 현재부터 미래까지 운영에도 대처하고 과거 데이터의 Backfill에도 대처할 수 있음
airflow가 없다면 과거 데이터 backfill이 어려움. 문제가 발생하는 지점으로 가기 어려움
backfill을 코드 변경없이 가능하게 함
멱등성
데이터 파이프라인이 연속 실행되었을 때 소스에 있는 데이터가 그대로 DW로 저장되어야 함
full refresh를 하는 데이터 파이프라인이라면?
→ 먼저 DW의 관련 테이블에서 모든 레코드를 삭제
→ 데이터 소스에서 읽어온 데이터를 DW 테이블로 적재
이것을 트랜잭션으로 묶어줘야함
DELETE FROM : 조건에 맞는 레코드들만 삭제
TRUNCATE : 조건없이 모든 레코드 삭제
BEGIN 이후에 나온 SQL은 ENDSK COMMIT이 나오기 전까지 적용안됨
Airflow Operators, Variables and Connections
중요한 DAG 파라미터 (not task parameters) → CPU 수에 의해 upper bound가 정해짐
max_active_runs : DAG 인스턴스의 개수. 같은 DAG가 동시에 몇 개 실행될수 있는지. backfill할 때 유의미한 파라미터
max_active_tasks : 병렬로 실행할 수 있는 task의 개수. DAG 아래 속한 task 들이 동시에 몇 개 실행될 수 있는지. 1이면 1개씩 실행. task 의존도에 따라 의미가 있을수도 있고 없을 수도 있음. 서버에 CPU가 2개이면 한 번에 2개까지만 가능
catchup : 과거 run들을 backfill 할지말지
DAG 파라미터 vs Task 파라미터 이해 중요!
DAG 파라미터는 DAG 객체를 만들 때 지정해주어야 함
default_args로 지정해주면 에러는 안 나지만 적용이 안됨
→ default_args로 지정되는 파라미터들은 태스크 레벨로 적용되는 파라미터들
Xcom 객체
task들간 값을 주고받을 수 있음.
데이터가 커지면 xcom을 이용할 수 없음. S3에 저장 후 포인터를 저장해야 함.
Primary key Uniqueness 보장하기 Upsert
데이터 웨어하우스들은 Primary key를 보장하지 않음
Primary key 유지 방법
임시 테이블(스테이징 테이블)을 만들고 거기로 현재 모든 레코드를 복사
임시 테이블에 새로 데이터소스에서 읽어들인 레코드들을 복사 → 이 때 중복 존재 가능
중복을 걸러주는 SQL 작성 → ROW_NUMBER를 이용해서 primary key로 파티션을 잡고 적당한 다른 필드(보통 타임스탬프 필드)로 ordering을 수행해 primary key 별로 하나의 레코드를 잡아냄
위의 SQL을 바탕으로 최종 원본 테이블로 복사
'Data Enginerring > 데이터 엔지니어링 스타터 키트' 카테고리의 다른 글
| 프로그래머스 데이터 엔지니어링 스터디 9기 수강 후기 (0) | 2022.09.21 |
|---|---|
| [6주차] Airflow 심화학습 (1) | 2022.09.21 |
| [4주차] ETL(Extract, Transform and Load)과 Airflow (0) | 2022.09.14 |
| [3주차] 데이터 엔지니어링을 위한 SQL (0) | 2022.09.12 |
| [2주차] Cloud & AWS 그리고 Redshift (0) | 2022.09.08 |